Tyler Cowen on Deep Research:
Deep Research
by Tyler Cowen February 4, 2025 at 2:58 pm
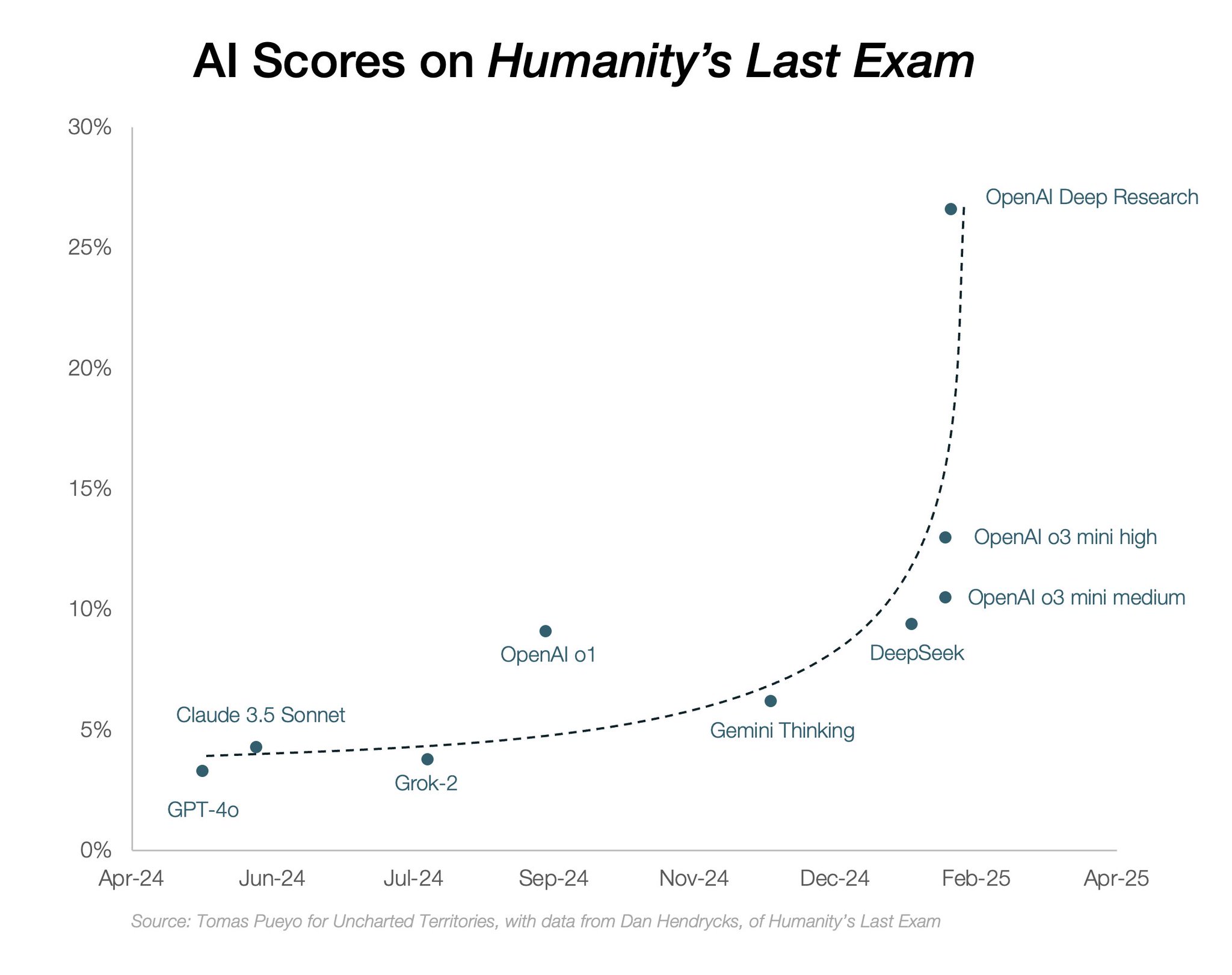
I have had it write a number of ten-page papers for me, each of them outstanding. I think of the quality as comparable to having a good PhD-level research assistant, and sending that person away with a task for a week or two, or maybe more.
Except Deep Research does the work in five or six minutes. And it does not seem to make errors, due to the quality of the embedded o3 model.
It seems it can cover just about any topic?
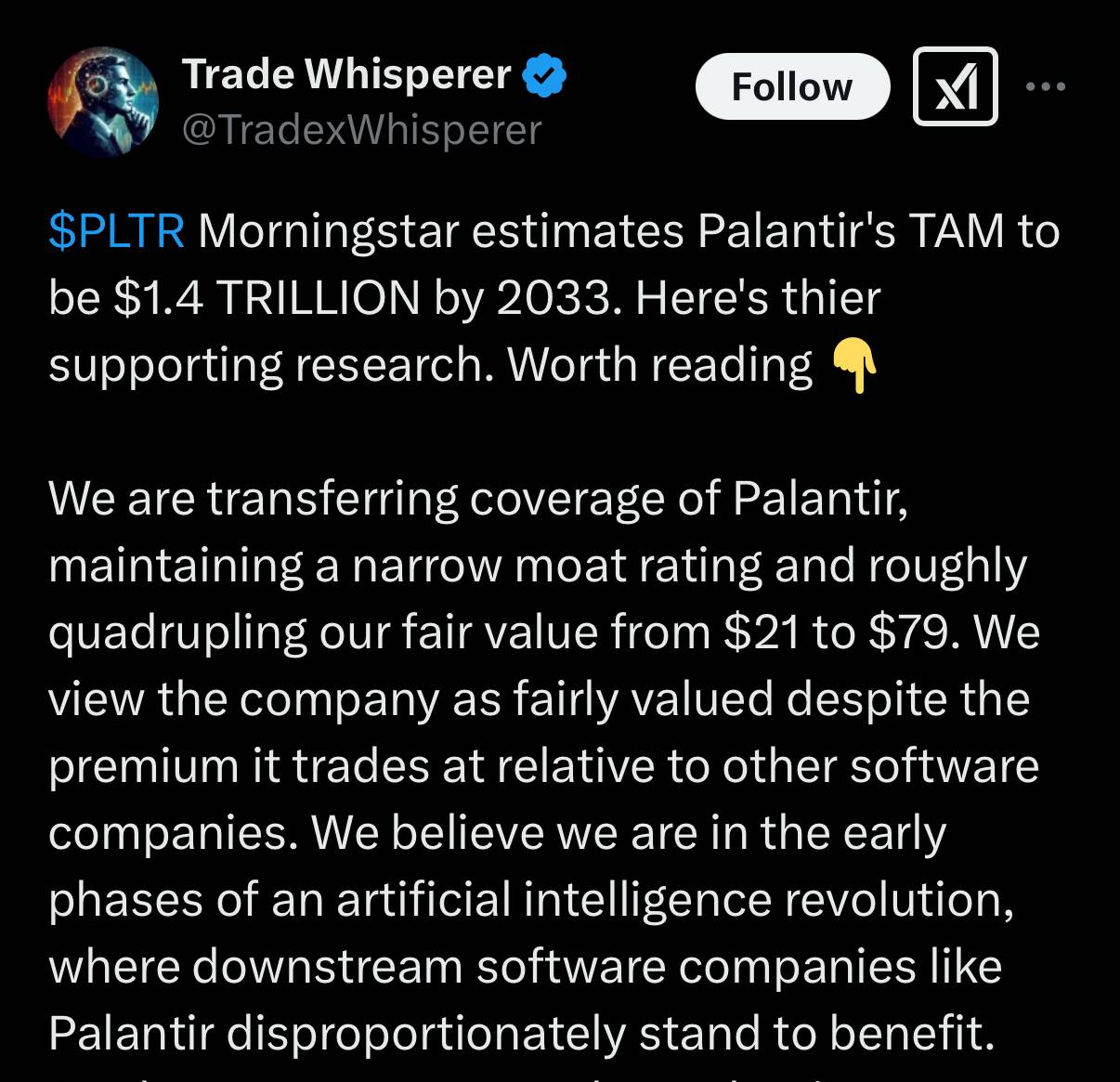
I asked for a ten-page paper explaining Ricardo’s theory of rent, and how it fits into his broader theory of distribution. It is a little long, but that was my fault, here is the result. I compared it to a number of other sources on line, and thought it was better, and so I am using it for my history of economic thought class.
I do not currently see signs of originality, but the level of accuracy and clarity is stunning, and it can write and analyze at any level you request. The work also shows the model can engage in a kind of long-term planning, and that will generalize to some very different contexts and problems as well — that is some of the biggest news associated with this release.
Sometimes the model stops in the middle of its calculations and you need to kick it in the shins a bit to get it going again, but I assume that problem will be cleared up soon enough.
If you pay for o1 pro, you get I think 100 queries per month with Deep Research.
Solve for the equilibrium, people, solve for the equilibrium.




")